| A rendezett minta |
1. A matematikai statisztika jellemzéseA matematikai statisztika elemei
A matematikai statisztika a véletlen (valószínûségi) változókkal jellemezhetõ (továbbiakban véletlen) rendszerek leíró adatainak feldolgozásáról, értelmezésérõl és felhasználásáról szóló tudományos módszertan.
Amíg a valószínûségszámítás fogalmai axiomákkal összhangban definiált vagy azokból levezetett absztrakt fogalmak, amelyek tulajdonságai ílymódon adottak, a matematikai statisztika megfigyelt, leszámlált vagy mért sajátságokat feleltet meg a valószínûségszámítás absztrak fogalmainak, sokszor megállapodásszerû módon. Szokásos mondás: "amíg a valószínûségszámítás megtanit valószínûségekkel számolni, addig a statisztika megtanit valószínûséget mérni".
Miután a véletlen által befolyásolt jelenségek nem biztos kimenetelûek, a matematikai statisztikában nincsenek biztos ítéletek. A matematikai statisztika becsül, megbecsülhetõ valószínûségû ítéleteket hoz.
Igen ritka az az eset, amelynél egy véletlen rendszer viselkedését minden elképzelhetõ kimenetelnél meg lehet figyelni. A matematikai statisztika következésképpen csak a rendszer valamely szemügyre vett részletébõl, valamely folyamat pillanatnyi állapotából, tehát a rendszer egy mintájából következtet magára a rendszerre. Ez a statisztikus megállapítások bizonytalanságának további oka.
A matematikai statisztika feladata tehát (1) jellemzõ számadatok, megállapítások levezetése, bemutatása megfigyelt adatokból, (2) valószínûség hozzárendelése a kapott vagy levont következtetésekhez, (3) döntés valamely fent alapon megfogalmazott állítás (hipotézis) elfogadásáról vagy elvetésérõl, végül, (4) olyan kisérleti feltételek meghatározása (olyan kisérletek tervezése), amelyek számunkra az állítások megbízhatósága szempontjából legkedvezõbbek.
2. Leíró és felderítõ statisztika
Vizsgált rendszereink vagy teljesen ismeretlenek vagy vannak
róla elõzetes (a priori) ismereteink. Ha vannak, képesek
vagyunk többé-kevésbé alkalmas (adekvát)
matematikai modellt alkotni, és ez esetben a statisztikai
adatgyüjtés célja a modell paramétereinek
megbecslése. Ha nincsenek elõzetes ismereteink, a leíró
és felderítõ statisztika módszereit alkalmazzuk,
amelyekre persze a modell alapú vizsgálatoknál is
szükség van. A felderítõ statisztika az adatok,
a minta kezelésére, jellemzésére, ábrázolására
vonatkozóan ad útmutatásokat, több változó
esetén pedig számos további feladatot old meg (alakfelismerés,
csoportosítás, osztályozás).
Viszgálatunk tárgya egy rendszer. Egy rendszernek elemei (objektumai) vannak, az objektumoknak tulajdonságai.
(Objektumok például: emberek, társadalmak, folyók, biotópok, oldatok, spektrumok, tulajdonságok az emberek testméretei, emberek, társadalmak, folyók, biotópok, oldatok, spektrumok, tulajdonságok az emberek testméretei, a társadalmak lakosságszáma, nemzeti jövedelme, a folyók vízhozama adott idõben, helyen, biotópok fajainak száma, egyedsûrüsége, oldatok koncentrációi, spektrumok csúcsmagasságai adott hullámhosszon stb.)
Egy rendszernek általában sok objektuma, azoknak sok, számos esetben végtelen sok értékû tulajdonsága van. A rendszert alkotó objektumok, pontosabban azok tulajdonságait leíró (végtelen) sok jellemzõ változó adat alkotja az adatok sokaságát. A sokaság elemei tehát lehetnek fizikai létezõk, de elméletiek is. A sokaság szabatos meghatározása fontos feltétele a statisztikai munkának, hiszen ez jelenti a feldolgozásra váró adatok pontos meghatározását.
(Egy folyó vizállása április 16-án és november 1-én például két statisztikai sokaság).
Általában csak arra van módunk, hogy a rendszer egy részletét, vagy egy bizonyos állapotát figyeljük meg, azaz annak leíró adataiból mintát vegyünk. Szokás mondani: a sokaság az összes elképzelhetõ minta halmaza.
A minta vizsgálatának eredményébõl következtetünk a sokaságra, a minta vétele tehát az eredmények értéke szempontjából elsõrendûen fontos. A minta legyen
- reprezentatív, összetételében képviselje helyesen a sokaságot, amelybõl vették,
- véletlen, a mintaelemek kerüljenek egymástól függetlenül, egyenlõ valószínûséggel a mintába,
- elégséges méretû, elegendõen nagy ahhoz, hogy a minta alapján levont következtetések kellõen valószínûek legyenek.
Az adatokat kategorikus és nem kategorikus (kvantitatív)
jellegûekre szokás felosztani. A kategorikus adatok alapján
az objektumokat osztályozni lehet. A kategorikus adatok lehetnek
nevesítõek
(nominálisak) és rendezõek (ordinálisak).
A nevesitõ adat egy-egy objektumot valamely (esetleg egyelemû)
osztályba osztályba sorol, a rendezõ adat már
sorrendet is definiál. (3.1/a táblázat)
3.1/a táblázat. Kategorikus adatok
|
|
|
|
| Nevesítõ (nominális) | = , ¹ | Nem, név, állampolgárság, foglalkozás, telefonszám |
| Rendezõ (ordinális) | = , ¹ , < , > | Iskolai osztályzat, rang, betegség foka, IQ |
Azokat a kategorikus adatokat, amelyek csak két osztály valamelyikébe sorolhatnak, dichotómikus vagy bináris adatoknak nevezik.
(Dichotómikus adatok: férfi-nõ, igaz-hamis, kicsi-nagy, beteg-egészséges)
A kvantitatív adatok lehetnek folytonos vagy diszkrét
(mérhetõ vagy leszámlálható, gyakran
metrikusnak
nevezettek) adatok. Szokásosan megkülönböztetik azokat
adatokat, amelyek skálájának önkényes
a 0-pontja,.lényegében különbségük
értelmes (intervallum skála) azoktól, amelyekre multiplikatív
aritmetikai mûveletek is alkalmazhatók (arányos skála).(3.1/b
táblázat).
3.1/b táblázat. Metrikus adatok példái
|
|
|
|
| Intervallum | Potenciál, Celsius fokban mért hõmérséklet | Naptári napok |
| Arányos | Tömeg, Abszolút hõmérséklet | Részecskeszám |
Vegyészi gyakorlatunkban az esetek túlnyomó részében
metrikus adatokkal (tömeg, anyagmennyiség, térfogat,
koncentráció, nyomás, hõmérséklet,
energiák sebességek) van dolgunk.
3.1.2 Az adatok kezelése, a skálázás
A sokaságból vett n elemû minta i-edik
adata egy:
| mintaelem xi i = 1,2 n (3.1) |
A mintaelemek sorozata a
| minta x = x1, x2, ,xn (3.2) |
ahol i index az adat mérési sorszáma.
Ha a minta adatait nagyságuk szerint állítjuk sorba,
a
rendezett mintához jutunk:
| A rendezett minta |
Egy minta természetes terjedelmét a számegyenesen a legkisebb és legnagyobb értékû mintaelem határozza meg. Különbozõ okokból szükség lehet arra, hogy ezt a terjedelmet módosítsuk, hogy az adatokat más egységben, más skálán tekintsük. Ezt skálázással lehet elérni, amelynek során az eredeti mintaelemekhez valamely számot hozzáadunk, vagy/és azokat valamely azonos számmal osztjuk. A számos skálázási lehetõség közül a vegyészi gyakorlatban a mértékegységváltás, a minta normálása 0 és 1 értékközé (móltört, tömegtört megadás), a minta centrálása, és a minta standardizálása leggyakoribbak.
Normált mintához jutunk, ha az eredeti minta minden elemét az elemek összegével osztjuk. Ennek egy eleme:
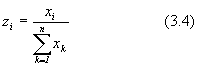
Felhívjuk a figyelmet arra, hogy az így normált adatok között egy már független a többitõl, az adatok összegébõl és a n - 1 adatból a függõ már kiszámítható.
Centrált minta keletkezik, ha minden elembõl kivonjuk az elemek átlagát (l. 3.7 képlet):
![]()
A centrált mintában szükségképpen pozitiv és negatív értékek lépnek fel, az elemek összeg 0. Ebbõl következik, hogy a centrált adatok közül is csak n - 1 darab független.
A standardizált lesz a minta akkor, ha az eredeti mintaelemekbõl kivonjuk azok átlagát és a különbségeket a minta empirikus szórásával (l. 3.10 képlet) osztjuk:
![]() (3.6)
(3.6)
A standardizált minta 0-közepû, szórása
1
Mintákról szemléletes képet ad a pontsor,
azaz a mintaelemek ábrázolása a számegyenesen,
az (egyváltozós) szóródási kép
(univariate scatter plot).
3.1. példa: Tekintsünk egy 24 elemû
mintát:
|
99, 117, 57, -35, 60, -117, -95, -16, 14, 29. 58, 87 |
Rendezve:
|
14, 29, 33, 57, 58, 60, 67, 87, 99, 107, 113, 117 |
Pontsorral ábrázolva:
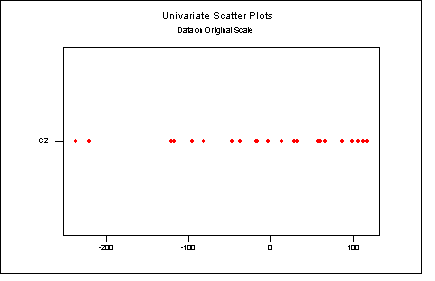
3.1 ábra Pontsoros ábrázolás
| Tartalom | http://www.chemonet.hu/hun/eloado/stat/
http://www.kfki.hu/chemonet/hun/eloado/stat/ |